Новые заметки по сканированию.
Переносы в словах. FineReader 6
В FineReader'e 6 при переносе слов со строки на строку я просто сшивал слова удалением дефиса-переноса. Теперь я понял, что лучше заменять дефис переноса 'мягким переносом используя горячие клавиши CTRL + '-'. Тогда в случае сохранения в pdf - это будет более корректно. Разбиение на строки останется как и было в книге. (06.08.2003)
Некоторые заметки по сканированию
это беспорядочные заметки - для самого себя, но поскольку в последнее время мне стали задавать вопросы ┘ я решил просто выкладывать обновления по этому поводу. Если кто-то может мне что-то подсказать - буду благодарен.
Переносы в словах. FineReader 6
I. Мое форматирование в Word'е. Между Интернетом и Сканированием - Word обязателен.
Мой стиль Book или Page или Bookpage
Как разбить мою книгу в Word на страницы
1. Поэтому вы идете в replace (заменить)
Введение разрыва страницы после номера страницы.. 5
2. В пункте 'Найти' ==> выбираете 'Формат' ==> 'Стиль' ==> BookPage или Book
3. выбираете BookPage или book в найти:
4. В заменить: 'Специальный' ==> 'Искомый текст'
5. Затем добавляете 'Разрыв страницы'
1. При сканировании я использую
2. Использовать интерфейс FineReader'a
4. Разрешение при сканировании
3. Экономия времени сканирования
2. Расположение книги на сканере
4. Точная подгонка размеров для сканирования
2. Сохранить текст с делением на строки
3. Опция 'Авто' в Распознавании
4. 'Форматированный пробелами'
IV. Передача файла из FineReader'a в Word
1. Что делать чтобы сохранить нумерацию страниц?
1. Номер страницы входит в текстовый блок
2. Номера страниц, как отдельные текстовые блоки расположенные параллельно
3. Номера страниц, как отдельные текстовые блоки расположенные параллельно - крупнее
4. Сохранять полное форматирование
6. Сохранять начертание и размер шрифта
2. Если же страницы комбинируются с колонтитулами, как указано ниже ┘
1. Номера страниц и колонтитулы - 1
2. Номера страниц и колонтитулы - 2
3. Номера страниц и колонтитулы - 3
5. Заметить все в FineReader'e - стирая искомый текст
6. Заметить все в FineReader'e - заменяя искомый текст
3. Кое-что из анализа макетирования.
4. Номер страницы пакета соответствует номеру изображения tiff в папке пакета
4. Какое будет разрешение графических файлов передаваемых из FineReader'a в Word?
2. Разрешение картинок при передаче в Word
Почему я сканирую?
Когда я впервые купил компьютер, а это был book(Macintosh), я полагал что вот пойду в Интернет и найду себе книжки┘
Но Интернет в 1995 - это был полный ноль.
Нашел я там - только Максима Мошкова. Это была удача. Он очень интеллигентный человек, что нынче редкость.
Но┘ фантастику я не читаю - а остального в сети тогда вааще не было.
Вот я и купил сканер, новый комп для программы FineReader и попробовал сам сканировать.
Сканировал я по двум причинам.
1. Мы очень много были на гастролях и на гастролях я мог читать книги на буке.
2. Я мог уехать надолго в Нью-Йорк и тогда моя библиотека была бы со мной.
Тем более заметки и компиляции прочитанных книг.
Вообще-то до недавней поры, у меня складывалось впечатления что для русских Интернет - это только газета.
В информационном смысле.
Если только вы не платите за что-то кому-то деньги.
О моих терминах
Страница - Лист - Разворот
Мне привычнее использовать слово страница пакета - как лист из двух страниц книги. Видимо потому, что я сканировал, как правило, сложные книги - в которых иногда по пять языков на каждом развороте. Поэтому мне удобнее распознавать и проверять сразу две страницы без разделения страниц по отдельности.
I. Мое форматирование в Word'е. Между Интернетом и Сканированием - Word обязателен.
Вы можете просто посмотреть разницу между моим форматированием книги Лотмана в Word'e и не моим форматированием другой книги Лотмана без Word'a а напрямую, видимо, из FineReader'a.
http://catalog.booksite.ru/localtxt/lot/man/lotman_u_m/o_po/etah/i_poe/zii/o_poetah_i_poezii/index.htm - это не мой вариант
и мой вариант Семиосферы Лотмана:
СЕМИОСФЕРА - html и zip
Мое сравнение этих двух книг - находится здесь:
http://yanko.lib.ru/books/error-fort/slava-sos-1.htm
1. Форматирование
Смысл моего форматирование в Word'е сводится к тому, чтобы определить каким заголовкам книги будут соответствовать определенные уровни заголовков в Word'е. 1-2-3-4. Чаще на этом уровни заканчиваются.
Все, что ниже четвертого может быть моей самодеятельностью, но если я это делаю, то предупреждаю.
2. HTML - Word
Какую бы версию html или word вы не взяли из сайта - это уже теперь не имеет значения, так как все нынче конвертируется в Word'е туда-сюда без потерь.
Если вы взяли html, то легко открываете его в Word'е и сохраняете как Word или наоборот - взяв Word в зипе сохраняете его как html.
Все, что вам надо - это - либо распечатать на принтере, либо удобно читать и редактировать - вот для этого вам Word и нужен, так как в html вы тупо читаете и не редактируете.
Html я выкладываю в сеть только потому, что это интернет и поисковые машины могут найти эту книгу - если вааще она кому-то нужна J
Word я выкладываю - только потому, что многие до сих пор не знают, что html легко конвертируется нынче в Word - и я тупо это делаю. Правда зип проще бросать к себе на хард.
И пространства на харде у Максима Мошкова это занимает в два раза больше. Увы.
Боже, огромное спасибо Максиму!!! Если бы не он, страшно подумать что было бы с совком.
3. Страницы
В последнее время страницы я форматирую отдельным стилем, т.е. по сути - тоже заголовком и именно для того, чтобы можно было вернуть книгу к ее бумажному варианту разбиения на страницы. Но заголовок этот скрыт. Если вы видите - страницы выделены отдельным цветом - то это именно то, о чем я говорю.
Мой стиль Book или Page или Bookpage
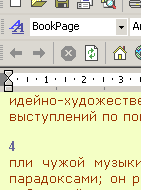
обычно этим цветом -
цвет стиля
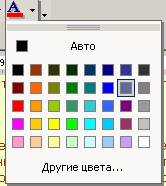
назвал я этот стиль либо book либо bookpage
Мои форматы книг
Я обычно выкладываю в сеть книги в формате HTML или zip. Если zip, то это сжатый Word 2002. В зависимости от того Вода который последний. Тему версии Вода я не обсуждаю, так как, чем более новый - тем более удобно в нем работать.
Так вот┘
Что это значит?
А значит это то, что благодаря этому вы за несколько секунд можете сами разбить книгу на страницы как это было в бумажном виде.
Как разбить мою книгу в Word на страницы
Нажимаете
Знак абзаца

чтобы видеть форматирование

по абзацам видно, что разрыва по страницам нет - это хорошо для html, но плохо для распечатки на принтере.
1. Поэтому вы идете в replace (заменить)
Введение разрыва страницы после номера страницы
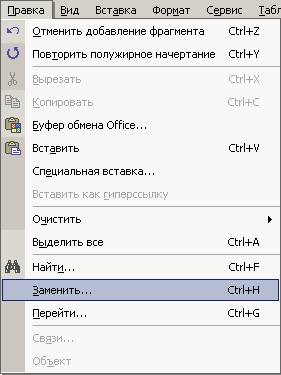
выбор стиля в Replace
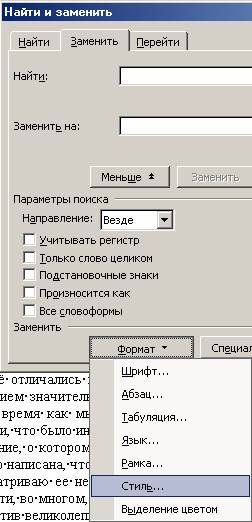
2. В пункте 'Найти' ==> выбираете 'Формат' ==> 'Стиль' ==> BookPage или Book
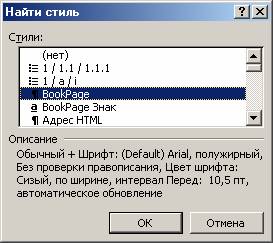
3. выбираете BookPage или book в найти:
4. В заменить: 'Специальный' ==> 'Искомый текст'
Введение искомого текста
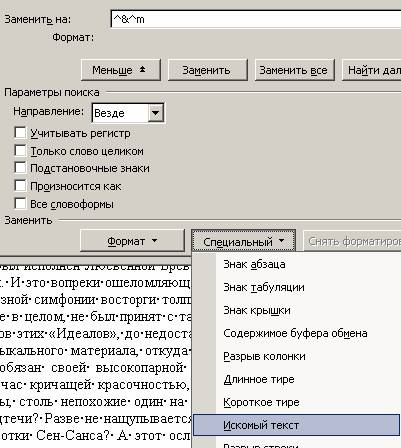
5. Затем добавляете 'Разрыв страницы'
Введение разрыва страницы
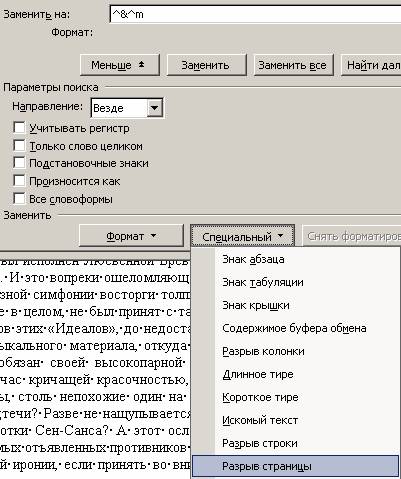
или просто вручную пишете ^&^m - что одно и тоже, если знаете обозначение специальных символов в Word'е
Далее нажимаете кнопку Заметь все
![]()
И ┘ ВСЕ
Итог

Как видите появился знак разрыва страницы.
Теперь вся книга разбита на страницы, как в бумажном виде книги.
Некоторые таблицы в Word
Например вот такая таблица из книги Холоповой 'Музыкальные формы'
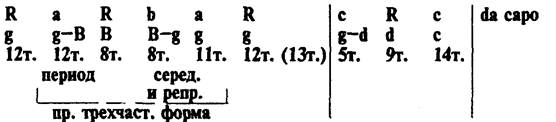
как из нее сделать такую таблицу?
|
R |
а |
R |
b |
а |
R |
с |
R |
с |
da capo |
|
g |
g-B |
В |
B-g |
g |
g |
g-d |
d |
с |
|
|
12т. |
12т. |
8т. |
8т. |
11т. |
12т. (13г.) |
5т. |
9т. |
14т. |
|
|
|
период |
|
серед. |
|
|
|
|
|
|
|
|
|
и репр. |
|
|
|
|
|
||
|
|
пр. трехчаст. форма |
|
|
|
|
|
|||
Достаем панель 'Таблицы и границы'
а именно:
Панель Таблицы и границы

Нам нужно подрисовать некоторые ячейки - выделить их каймой.
- Выбираем толщину линии, цвет
- Выбираем карандаш и рисуем кайму
Выбираем толщину линии

Цвет линии

Карандаш рисования таблицы

Рисуем в ячейке кайму

![]()
будет лучше виднее если выбрать красный

и таким образом получим
|
R |
а |
R |
b |
а |
R |
с |
R |
с |
da capo |
|
g |
g-B |
В |
B-g |
g |
g |
g-d |
d |
с |
|
|
12т. |
12т. |
8т. |
8т. |
11т. |
12т. (13г.) |
5т. |
9т. |
14т. |
|
|
|
период |
|
серед. |
|
|
|
|
|
|
|
|
|
и репр. |
|
|
|
|
|
||
|
|
пр. трехчаст. форма |
|
|
|
|
|
|||
Или так виднее
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|||
Вот и все.
II. Сканирование
1. При сканировании я использую
1.
Программу Fine Reader 6 pro (?)
2. Сканер UMAX Astra 1200S ($270-320) теперь около $100
3. Редактирую HTML в
Word 2002.
Янко Слава (библиотека Fort / Da) yanko_slava@yahoo.com | | http://yanko.lib.ru || Icq# 75088656
update 17.05.03
2. Настройка сканирования
Нужно выбрать режим сканирования 'В Интерфейсе FineReader'а', иначе это будет АД. Стоит сразу выбрать галочку в разделе Инвертирования.
1. Опции
2. Использовать интерфейс FineReader'a
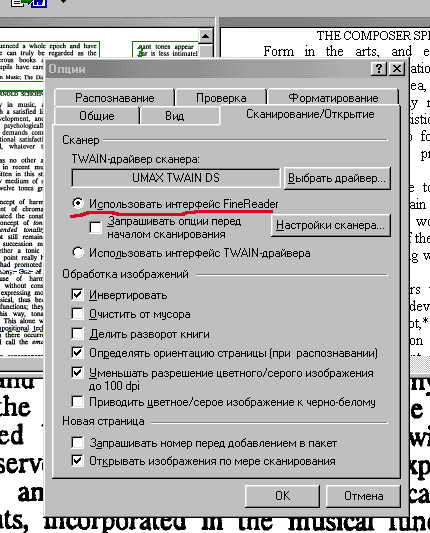
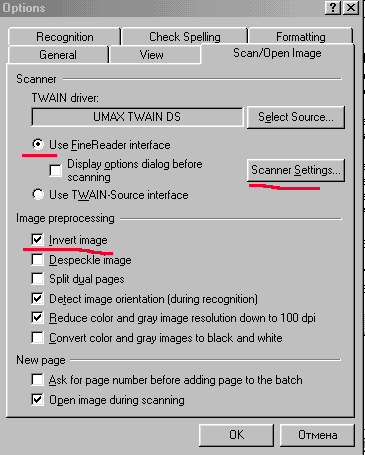
Сканировать же книгу 'В Менеджере TWAIN' - означает в каждой странице заново размечать область сканирования:
3. Менеджер TWAIN
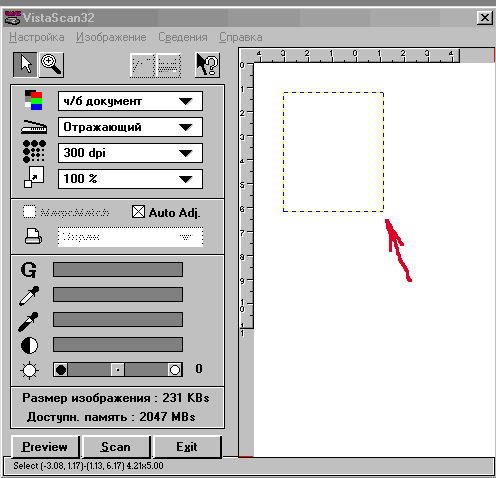
В настройках сканера 'В Интерфейсе FineReader'а' выбрать размер области сканирования и поставить по умолчанию 'Разрешение - 300':
4. Разрешение при сканировании
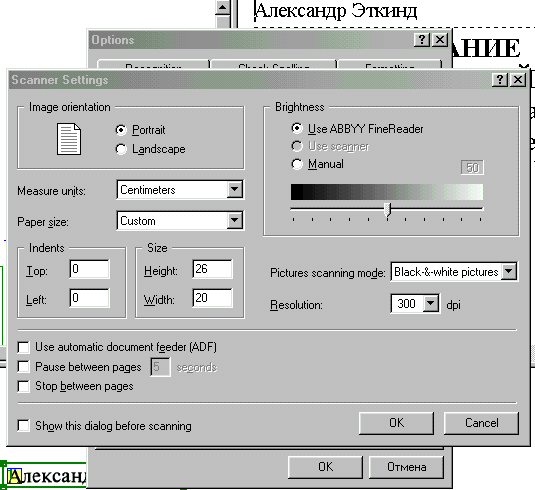
3. Экономия времени сканирования
Именно в этом окне нужно выставить размеры поля сканирования для экономии времени в полтора раза.
Вот как это будет выглядеть если не уменьшить поле сканирования:
1. Размеры поля сканирования

Все выделенное красным цветом - лишнее.
Поэтому я кладу книгу так, чтобы она упиралась в ближний ко мне угол сканера. Не ребро, а угол. Т.е. прижимаю книгу к верхнему ближнему ко мне углу.
2. Расположение книги на сканере
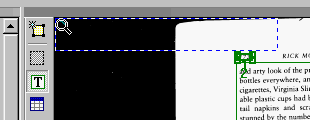 - здесь угол книги не прижат углу, а здесь
прижат:
- здесь угол книги не прижат углу, а здесь
прижат: 
В последнем варианте нет ничего лишнего между углом сканера и книгой.
Затем выставляю размеры поля сканирования.
3. Размеры сканирования

и тогда разворот книги в две страницы точно попадает в поле сканирования без излишков, что сильно экономит время.
4. Точная подгонка размеров для сканирования

III. Распознавание текста
Проблема со стихами
Если в тексте встречаются стихи, то как правило они не разбиваются корректно на строки.
1. Стихи на странице

Есть два варианта:
1. Сохранять текст с делением на строки при передаче в Word, но как быть тогда с остальным текстом на странице и тем более книге вцелом?
Этой функцией я пользуюсь только в случае передачи в Word списков имен в конце книги или мелких комментариев почти табличного типа.
2. Сохранить текст с делением на строки
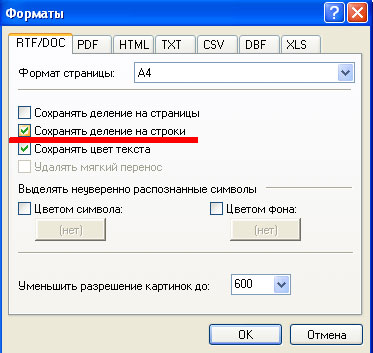
Это врядли хороший вариант.
2. Вариант 2:
1) Макетировать страницу так, чтобы стихи были в отдельном текстовом блоке. Как на рисунке.
2) После макетирования отдельным блоком - распознаете страницу. Ничего при этом не произойдет, но ┘
Не произойдет ничего нового потому, что у вас по умолчанию в опции: 'Распознавание' выбрано 'Авто'. Это хорошо для страницы вцелом, но плохо для стихов.
3. Опция 'Авто' в Распознавании
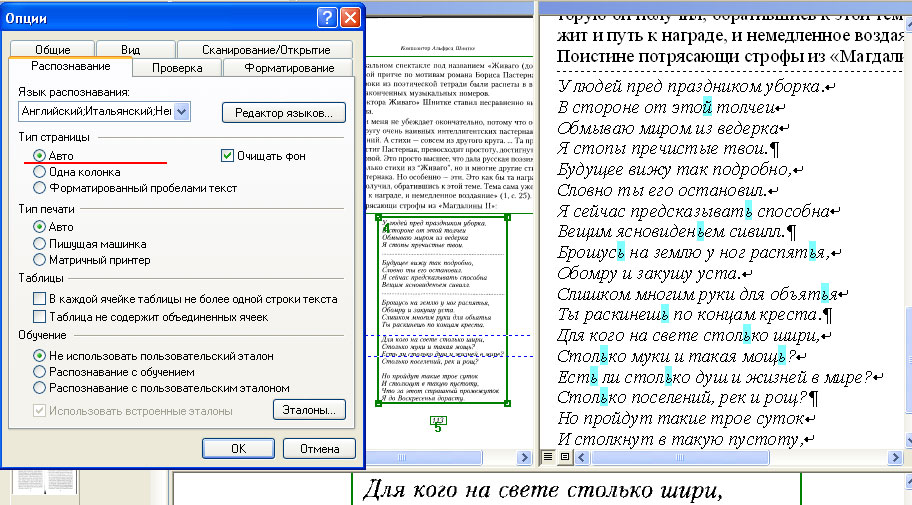
Это 'авто' означает что программа как бы сама пытается понять - что есть что┘
Но ей это неудается.
На изображении видно, что текст стиха будет в одну строчку и это например для книг Лотмана - ужасно.
Поэтому используем фишку программы по назначению:
После того как распознали всю страницу идем в опцию Распознавания и меняем 'авто' на 'Форматированный пробелами'
4. 'Форматированный пробелами'

После этого вы распознаете блок только со стихами и получаете похожее на правду.
Но при распознании в этом режиме нужно точнее размечать текстовый блок - иначе у вас появятся лишние пробелы.
Из-за того что часто приходится лазать в эту опцию - было бы замечательно, что бы FineReader следующей версии обладал этой опцией на панели или имел МАКРОСЫ для создания подобных опций.
IV. Передача файла из FineReader'a в Word
1. Что делать чтобы сохранить нумерацию страниц?
Нумерация страниц нужна для нормального цитирования. Поэтому я всегда сохраняю нумерацию страниц и все данные издательств и год выпуска книги.
Самый простой способ делать так, если страницы указаны подобным образом, не в комбинации с колонтитулами:
1. Номер страницы входит в текстовый блок
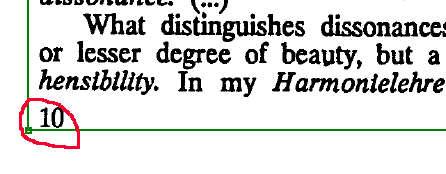
В этом случае все будет просто.
Но если у нас получается такой анализ макета страницы ┘
2. Номера страниц, как отдельные текстовые блоки расположенные параллельно
3. Номера страниц, как отдельные текстовые блоки расположенные параллельно - крупнее

то при передаче в Word в режиме ┘ 'Полного Форматирования'
4. Сохранять полное форматирование


получится неверное форматирование:
5. Что будет в Word'e если вы сохранили полное форматирование с параллельными номерами страниц в отдельных блоках

Но если вы передадите в Word страницы в режиме только 'Сохранять начертание и размер шрифта':
6. Сохранять начертание и размер шрифта

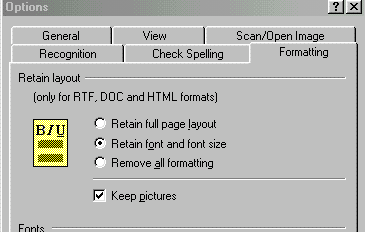
то страницы окажутся там где нужно. Всеравно нумерация страниц окажется там, где нужно.
2. Если же страницы комбинируются с колонтитулами, как указано ниже ┘
1. Номера страниц и колонтитулы - 1

2. Номера страниц и колонтитулы - 2
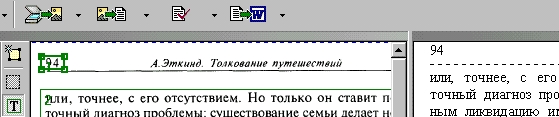
┘ то я, как видно, изгаляюсь в макетировании страницы вручную и потом редактирую в текстовом поле, если это нужно, но номер страниц сохраню.
Другой вариант:
3. Номера страниц и колонтитулы - 3

можно и так, но тогда я после распознавания хочу лишнее стереть в диалоговом окне Replace ('Заменить')
4. Заметить в FineReader'e

Выбираю: 'Заменить все' и просто стираю эту надпись.
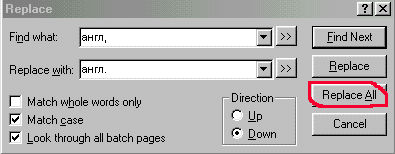
5. Заметить все в FineReader'e - стирая искомый текст
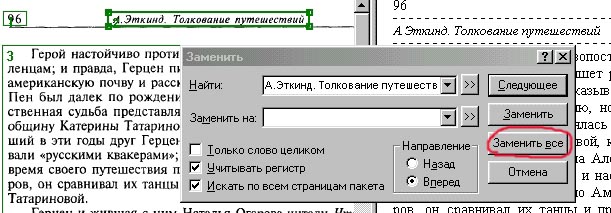
Рисунок 15. Заметить все в FineReader'e
6. Заметить все в FineReader'e - заменяя искомый текст
3. Кое-что из анализа макетирования.
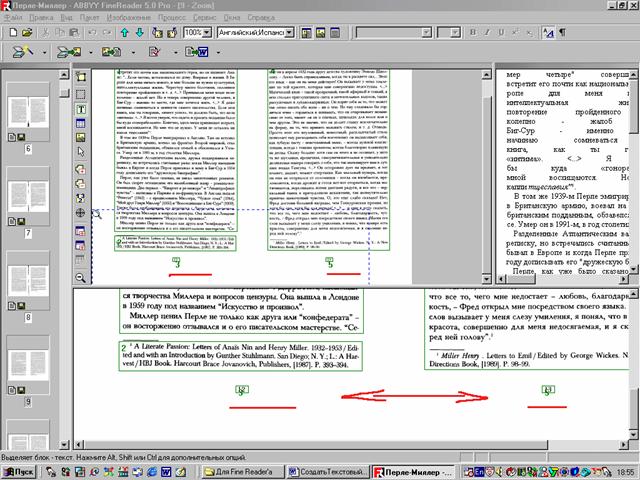
Вы можете открывать одно и тоже изображение FineReader'ом и оно всякий раз будет пониматься программой, как новое.
Иногда попадаются такие листы(две страницы в развороте), когда одна из страниц в книге читается вверх, другая, как все нормальные, вправо.
1. Разнобой в развороте

Можно конечно просто перед сканированием задать режим делить лист пополам - т.е. поставить галочку 'Делить разворот книги',
2. Делить разворот книги
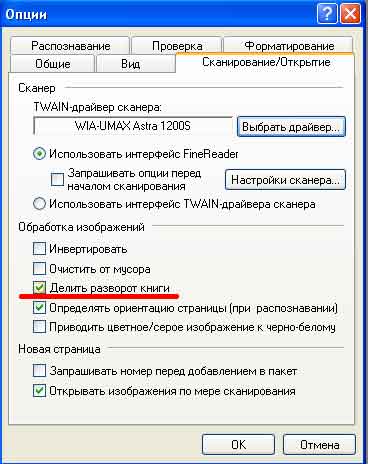
но сканирующие много - знают - между процессом сканирования и собственно распознанием страниц - проходят иногда месяцы и ты уже не помнишь подробностей сканирования данной книги. Главное чтобы сам процесс сканирования проходил в режиме автоматизма. Не занимал у сканирующего много внимания. Поэтому книгу проще сканировать листами, а не отдельными страницами, т.к. потом быстрее ее макетировать руками.
Но если иногда попадаются именно такие листы, то я хочу сделать простую вещь - из одного листа-страницы пакета - сделать две разные страницы.
Для этого я должен открыть тоже самое изображение страницы из уже отсканированного пакета и стерев ластиком все ненужное в дубликате - присвоить ей следующий номер - за номером искомой страницы.
Например, после стр. 22 открываю этоже изображение из этогоже пакета под номером 0022 (стр. 22 = 0022.tiff)
3. Открыть изображение

4. Номер страницы пакета соответствует номеру изображения tiff в папке пакета

Как только я ее открыл - она ляжет в конец пакета, как новая страница - и в папке пакета она появится как новое изображение с новым номером.
После этого я делаю с ней то, что мне нужно - например, переворачиваю ее, стираю изображение одной из страниц и затем┘
с помощью манипуляций с номерами страниц в пакете встраиваю ее следующим номером после той же самой изначальной страницы.
Таким образом, я хочу сказать то, что вы можете открывать одно и тоже изображение FineReader'ом и оно всякий раз будет пониматься программой, как новое.
4. Какое будет разрешение графических файлов передаваемых из FineReader'a в Word?
Т.е. насколько они будут хороши в Word'e?
Когда я стал сканировать книги о музыке в которых есть нотные примеры пришлось узнать вот что┘
В разделе FineReader'a 'Форматирование'
1. Форматы
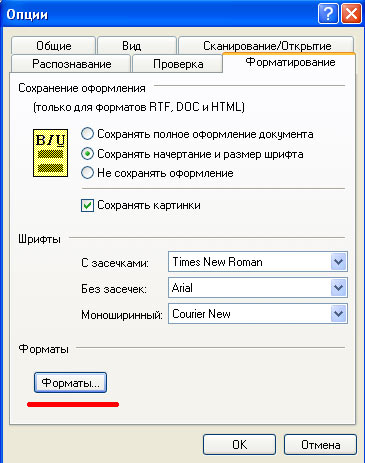
внизу окна
2. Разрешение картинок при передаче в Word
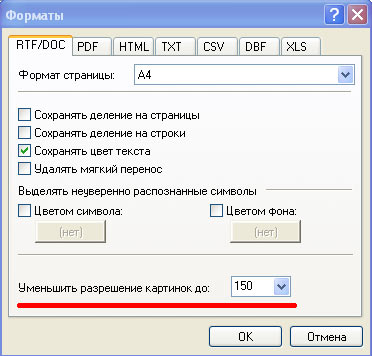
по умолчанию стоит разрешение 150 пикселей - ВОТ ТУТ-то и весь фокус ┘
Вы можете отсканировать изображение с любым разрешением, но здесь оно будет сведено к минимуму при передаче в Word..
Поэтому измените здесь разрешение на максимальное:

и оно не будет ниже того, с каким вы его отсканировали ┘ выше оно не будет - так же J
Не зная этого нюанса было очень обидно получать плачевный результат.
Я сканировал книгу с высоким разрешением а потом получал невразумительные фото в Word'e.
Вы можете проделать простейший эксперимент.
Отсканируйте фото с разрешением 400-600 из FineReader'а. После этого распознайте его в FineReader'e и передайте в Word и вы сразу увидите разницу.
IV. Заморочки
TWAIN - Vista Scan
Мой драйвер TWAIN имеет дурное свойство - а именно, терять ориентиры светло-темно, т.е. его нужно порой 'ресетать' в самом менеджере. Тогда вы снова увидите разницу в установках светло-темно.
Успехов!!
Пишите┘
Сканирование и форматирование: Янко Слава (библиотека Fort/Da) slavaaa@yandex.ru || yanko_slava@yahoo.com || http://yanko.lib.ru || Icq# 75088656 || Библиотека: http://yanko.lib.ru/gum.html ||
update 03.09.03